
La primera opción de almacenamiento digital que se empleo fueron los archivos de acceso secuencial, ficheros con una cierta estructura para almacenar los datos pero muy lejos todavía de las bases de datos.
Pongámonos al inicio de la segunda mitad del siglo XX, cuando nuestro protagonista Antonio comienza a pasar a formato digital los datos de su tienda SuperGades. La opción que por entonces tiene disponible es sencillamente pasar los datos de un fichero en papel a un fichero digital, empleando un procesador de textos muy sencillo con muy pocas funcionalidades, en el que escribiríamos los datos sin ningún tipo de formato. A este fichero, se le denomina también archivo, tomando el nombre de su antecedente analógico, un fichero físico con cajones donde guardábamos las fichas con los datos. Si estuviéramos almacenando los datos de los proveedores, el archivo podría tener un aspecto similar a:
Frutas Gutierrez
Antonio Gutierrez
607454545
Hortalizas del Sur
Guillermo Morales
652854874
Azucarera Sevillana
Rodrigo Mendez
622525885
En este archivo hemos escrito los datos de nuestros proveedores uno detrás de otro, como lo haríamos en un cuaderno. Hemos generado un archivo secuencial, que recibe este nombre porque los datos se almacenan uno detrás de otro, y el acceso a los mismos será de forma secuencial, es decir, tengo que recorrer el archivo desde el principio hasta llegar al dato que quiero recuperar.
La marca EOF (End of File)
Esta manera de trabajar obligaba a incluir algún tipo de marca que nos indicara que habíamos llegado al final del archivo, de otro modo, obtendríamos un error al intentar leer un dato más allá del final del archivo. Esta marca es el carácter de final de archivo EOF.
Cuando escribíamos datos en el archivo, al cerrar el mismo, se añadía de manera automática este carácter al final del archivo.
Los lenguajes de programación emplean el carácter EOF en los procesos de lectura de datos. Van recorriendo el archivo de forma secuencial, línea a línea, dentro de un bucle hasta leer la marca EOF.
Limitaciones de los archivos secuenciales
El uso de archivos secuenciales para el manejo de datos presenta muchas limitaciones:
Acceso secuencial: como ya he mencionado antes, el acceso a los datos era secuencial, teníamos que recorrer todo el fichero desde su primera línea hasta llegar al dato que queríamos recuperar. Esta era la única manera de movernos por el archivo, siempre se avanzaba a leer la línea siguiente, no se podía retroceder, si queríamos recuperar un dato que ya habíamos pasado, teníamos que comenzar la lectura secuencial desde la primera línea.
Modos de apertura: Al acceder al fichero para trabajar con él, lo tenemos que abrir en modo de escritura o lectura, dependiendo de la operación que queramos realizar. Para cambiar de operación tenemos que cerrar el fichero y abrirlo de nuevo en el modo correspondiente.
Las lecturas pueden ser parciales, sin embargo las escrituras tienen que se completas. Cuando abrimos un fichero secuencial en modo escritura estamos borrando todo su contenido anterior. Por ejemplo, cuando queremos borrar un registro, lo que hacemos es reescribir el fichero completo, salvo el registro que queremos eliminar.
Algunos lenguajes de programación, permiten escribir a continuación del final de fichero. Un comando muy habitual para realizar esta función es Append.
Acceso exclusivo: Solamente un usuario puede trabajar sobre el fichero en un determinado momento, para que un nuevo usuario pueda acceder al fichero, el usuario actual tendría que cerrarlo antes. En otras palabras, no es posible que varios usuarios accedan al fichero de manera simultanea.
Estructura fija de campos: El propio funcionamiento de este tipo de archivos, nos obliga a manejar una estructura fija de datos. En el archivo ejemplo de proveedores primero guardábamos el nombre de la empresa, luego el nombre de la persona de contacto y finalmente el número de teléfono.
Cuando recorremos el fichero, sencillamente leemos datos, pero no sabemos que dato estamos leyendo. De esta forma, si cambiáramos accidentalmente el orden de registro, por ejemplo colocando primero el contacto y luego el nombre de la empresa, el dato de contacto sería tomado como el nombre de la empresa y el dato del nombre de la empresa como contacto.
Campos y registros
La estructura de almacenamiento de datos, la podemos definir en campos y registros. Un campo sería un tipo de dato y un registro sería el conjunto de campos que definen un elemento. Siguiendo con el ejemplo del archivo de proveedores, los campos de nuestra estructura serían: nombre del proveedor, contacto en el proveedor y teléfono. Y un registro sería el conjunto de campos que definen un elemento, en nuestro caso, un proveedor.
Pues bien, nuestro amigo Antonio, para evitar errores con los datos, decide realizar algunas mejoras en sus archivos secuenciales. Básicamente, introduce una marca de sincronismo, que nos indica el final de un registro. Esta marca puede ser cualquiera que definamos, pero una comúnmente empleada era <FIN>.
Con esta mejora, el archivo de proveedores quedaría:
Frutas Gutierrez
Antonio Gutierrez
607454545
<FIN>
Hortalizas del Sur
Guillermo Morales
652854874
<FIN>
Azucarera Sevillana
Rodrigo Mendez
622525885
<FIN>
Lógicamente, esta marca no podía ser nunca el valor de un campo, ya que nos conduciría a error, interpretaríamos dicho campo como el final del registro.
Soporte físico
En aquellos tiempos, Antonio emplearía cintas magnéticas para almacenar sus datos. Una cinta que se enrollaba sobre un rodillo, y que contenía partículas magnéticas para almacenar los datos. La cinta se iba desenrollando y se hacia pasar por un cabezal para su lectura o escritura, el mismo sistema empleado para las famosas cassettes de música. El propio funcionamiento de este sistema forzaba a que el acceso fuera secuencial, recorriendo la cinta de principio a fin.

Ejercicio: Practicar las operaciones de registro y lectura de datos en archivos secuenciales
En cualquier caso, para entender cómo funcionaba este sistema, lo mejor es experimentarlo en nuestras carnes. Para ello, vamos a crear un fichero secuencial, a leer y escribir datos en él.
Este ejercicio lo realizaremos con python.
Paso 1: Programamos un script para registro de datos
Lo primero que haremos será crear un archivo con los datos. Por ejemplo, con los datos de proveedores que manejaba Antonio. El script que realizaría esta tarea sería:
def crear_archivo():
# Abre el archivo en modo de escritura ('w')
with open('registros.txt', 'w') as archivo:
# Escribe algunos registros en el archivo
archivo.write("Frutas Gutierrez\n")
archivo.write("Antonio Gutierrez\n")
archivo.write("607454545\n")
archivo.write("Hortalizas del Sur\n")
archivo.write("Guillermo Morales\n")
archivo.write("625854874\n")
archivo.write("Azucarera Sevillana\n")
archivo.write("Rodrigo Mendez\n")
archivo.write("622525885\n")
# Crea el archivo y carga los registros
crear_archivo()
print("Archivo creado y registros cargados con éxito.")
Sin explicar en profundidad cómo funciona el programa, ya que este no es un curso de programación, sencillamente comentar que este crea el fichero de texto: “registros.txt” y luego escribimos los datos en él, de manera secuencial.
Paso 2: Ejecutamos el programa
Al ejecutar el programa, se nos crea el fichero “registros.txt” en la carpeta en la que este el programa.
Si abrimos ahora el fichero con el bloc de notas, obtenemos:
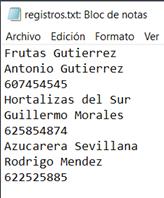
Hemos guardado los datos registrando un campo en cada línea. Como cada registro está compuesto de tres campos: Proveedor, Contacto y Teléfono, para recuperar un registro completo tendremos que leer tres líneas consecutivas.
Paso 3: Programamos un método para leer los datos del fichero
En mi caso lo llamo leer archivo y tendría el siguiente aspecto:
def leer_archivo():
# Abre el archivo en modo de lectura ('r')
with open('registros.txt', 'r') as archivo:
# Lee y muestra todos los registros
print("Leyendo datos del archivo:")
for linea in archivo:
print(linea.strip()) # Elimina caracteres de nueva línea al imprimir
Si ejecutamos el método, veremos que se nos imprimen en pantalla todos los datos del fichero. Para ejecutar el método tecleamos:
leer_archivo()Hemos ido leyendo los datos línea a línea de forma secuencial, y dibujando en pantalla cada línea del fichero. El resultado que obtenemos es:
Leyendo datos del archivo:
Frutas Gutierrez
Antonio Gutierrez
607454545
Hortalizas del Sur
Guillermo Morales
625854874
Azucarera Sevillana
Rodrigo Mendez
622525885
Paso 4: Programamos un método para buscar un registro, para recuperar los datos de un proveedor
Lo normal será que queramos recuperar los datos de un único proveedor, buscando por el nombre o por el contacto. Buscando por este último término, un posible método que realizaría esta función sería:
def recuperar_registro_por_nombre(nombre):
encontrado = False
registro_encontrado = []
with open('registros.txt', 'r') as archivo:
# Inicializa una variable para almacenar la línea actual
linea_anterior = ''
linea_actual = archivo.readline().strip()
while linea_actual:
if nombre.lower() in linea_actual.lower():
encontrado = True
# Agrega la línea anterior, la línea actual y la línea siguiente
registro_encontrado.extend([linea_anterior, linea_actual, archivo.readline().strip()])
print(f"Registro encontrado para {nombre}: {registro_encontrado}")
break
# Actualiza las líneas para el próximo ciclo
linea_anterior = linea_actual
linea_actual = archivo.readline().strip()
if not encontrado:
print(f"No se encontró registro para {nombre}.")
Si ejecutamos este método pasándole como nombre: “Antonio Gutierrez”:
# Ejemplo de uso:
nombre_a_buscar="Antonio Gutierrez"
recuperar_registro_por_nombre(nombre_a_buscar)
Obtendríamos el resultado:
Registro encontrado para Antonio Gutierrez: ['Frutas Gutierrez', 'Antonio Gutierrez', '607454545']El método lee el fichero línea a línea, y cuando encuentra el dato que buscamos, almacena en una lista la línea anterior, la línea encontrada y la siguiente, es decir, todo el registro.
Paso 5: Usando el formato csv
Hoy en día, el formato más habitual para este tipo de ficheros es el csv (fichero separado por comas). Vamos a repetir todo el proceso de trabajo pero empleando un fichero de este tipo.
Empezamos generando el fichero con el script:
def crear_archivo_csv():
# Abre el archivo en modo de escritura ('w')
with open('registrosformatoCSV.txt', 'w') as archivo:
# Escribe algunos registros en el archivo
archivo.write("Proveedor,Contacto,Telefono\n")
archivo.write("Frutas Gutierrez,Antonio Gutierrez,607454545\n")
archivo.write("Hortalizas del Sur,Guillermo Morales,625854874\n")
archivo.write("Azucarera Sevillana,Rodrigo Mendez,622525885\n")
Llamamos al método para crear el fichero
crear_archivo_csv()Si abrimos ahora el fichero con el bloc de notas, obtenemos:
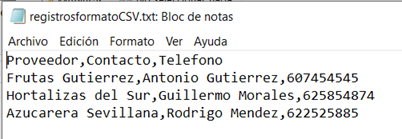
Hemos definido una primera fila que contendría los títulos o los nombres de los campos, lo que es una practica habitual en los ficheros csv. En este formato, los distintos campos se separan por comas y cada registro va en una línea.
Realizamos ahora un método para leer el archivo:
def leer_archivo_csv():
# Abre el archivo en modo de lectura ('r')
with open('registrosformatoCSV.txt', 'r') as archivo:
# Lee y muestra todos los registros
print("Leyendo datos del archivo:")
for linea in archivo:
print(linea.strip()) # Elimina caracteres de nueva línea al imprimir
Si ejecutamos ahora:
leer_archivo_csv()El resultado será:
Leyendo datos del archivo:
Proveedor,Contacto,Telefono
Frutas Gutierrez,Antonio Gutierrez,607454545
Hortalizas del Sur,Guillermo Morales,625854874
Azucarera Sevillana,Rodrigo Mendez,622525885
Ya sólo nos quedaría recuperar un registro que busquemos por un nombre, para ello podemos emplear el siguiente método:
def recuperar_registro_por_nombre_csv(nombre):
# Abre el archivo en modo de lectura ('r')
encontrado=False
with open('registrosformatoCSV.txt', 'r') as archivo:
# Busca el registro por nombre
for linea in archivo:
if nombre in linea:
encontrado=True
print(f"Registro encontrado para {nombre}: {linea}")
break
if not encontrado:
print(f"No se encontró registro para {nombre}.")
Si ejecutamos este método pasándole como nombre: “Guillermo Morales”:
recuperar_registro_por_nombre_csv("Guillermo Morales")Obtenemos:
Registro encontrado para Guillermo Morales: Hortalizas del Sur,Guillermo Morales,625854874NOTA:
Este post es parte de la colección “Sistemas de acceso y almacenamiento de datos”. Puedes ver el índice de esta colección aquí.