Para mostrar las distintas funcionalidades que provee pandas para explorar un dataFrame, vamos a trabajar con datasets precargados y así tendremos suficientes datos sin tener que introducirlos manualmente.
Pandas no incluye datasets precargados, pero podemos usar la libreria Seaborn que sí los incluye.
Para ver los datasets que proporciona Seaborn podemos usar el siguiente código:
import seaborn as sns
print(sns.get_dataset_names())
El resultado de ejecutar el anterior código es la lista de datasets:
Y para cargar un dataset de ejemplo con el que trabajar, usamos la función load_dataset() que recibirá como parámetro el nombre del dataset que queramos cargar. Por ejemplo, nosotros vamos a trabajar con el dataset ‘titanic’, que aunque está muy manido, resulta muy conveniente para aprender, ya que tiene un tamaño ideal y todo tipo de datos.
import seaborn as sns
df = sns.load_dataset('titanic')
Tras ejecutar el código anterior, tenemos los datos de ‘titanic’ en el dataframe df
Información básica de los datos
Para obtener la información básica de los datos, empezaremos empleando el método info(). Este método proporciona información sobre los tipos de datos y los valores nulos para cada característica (columna). En realidad, proporciona la información de los valores no nulos, pero como tenemos también la dimensión del datasets, con una simple resta, sabemos los valores nulos para cada característica.
import seaborn as sns
df = sns.load_dataset('titanic')
df.info()
Ejecutando el código anterior, obtenemos el resultado que devuelve la función info():
En primer lugar, nos indica que estamos trabajando con un objeto DataFrame. Este objeto tiene 891 entradas, con indices del 0 al 890. Y un total de 15 columnas (características).
Luego vemos las 15 columnas, enumeradas desde el 0 al 14, con su nombre, la cuenta de los valores no nulos y el tipo de dato.
Se obtienen datos de tipo numérico: int64 y float64, datos de tipo texto: object, datos de tipo booleano: bool y datos categóricos: category, que tienen un número finito de valores únicos.
Si únicamente quisieramos ver el tipo de dato, bastaría con que emplearamos el parámetro dtypes, como en el siguiente ejemplo de código:
import seaborn as sns
titanic = sns.load_dataset('titanic')
print(titanic.dtypes)
Dimensiones del dataset
Una de las primeras cosas que querremos conocer son las dimensiones de nuestro datasets, cuantas filas y cuantas columnas de datos tenemos. Si bien es cierto que la función info() ya proporciona esta información, es común usar el parámetro shape y de esta manera poder manejar las filas y columnas en dos variables independientes. El siguiente código muestra como:
El parámetro shape nos proporciona ambas dimensiones: filas y columnas, para el indice cero obtenemos las filas y para el indice 1 las columnas. El resultado de ejecutar el código anterior sería:
dimensiones: (891, 15)
filas: 891
columna: 15
Vistazo al dataset
Para hacernos una idea del aspecto de los datos, querremos echar un vistazo al dataset, es decir, ver algunos de sus registros. Lo más habitual es que dibujemos los primeros o los últimos.
Para extraer los primeros registros se emplea el método head(n), siendo n el número de los primeros registros que se quieren recuperar. De similar manera, para recuperar los n últimos registros, utilizamos el método tail(n). Por ejemplo, para recuperar los 7 primeros registros empleariamos: head(7)
n tiene un valor por defecto de 5, con lo que si no pasamos nada a head(), se presentaran los 5 primeros registros
import seaborn as sns
df = sns.load_dataset('titanic')
print(df.head(7))
El código anterior produce el siguiente resultado.
survived pclass sex age sibsp parch fare embarked class \
0 0 3 male 22.0 1 0 7.2500 S Third
1 1 1 female 38.0 1 0 71.2833 C First
2 1 3 female 26.0 0 0 7.9250 S Third
3 1 1 female 35.0 1 0 53.1000 S First
4 0 3 male 35.0 0 0 8.0500 S Third
5 0 3 male NaN 0 0 8.4583 Q Third
6 0 1 male 54.0 0 0 51.8625 S First
who adult_male deck embark_town alive alone
0 man True NaN Southampton no False
1 woman False C Cherbourg yes False
2 woman False NaN Southampton yes True
3 woman False C Southampton yes False
4 man True NaN Southampton no True
5 man True NaN Queenstown no True
6 man True E Southampton no True
Aquí podemos hacernos una mejor idea de los datos que tenemos en cada columna. En general, para los datos numéricos querremos conocer los principales estadísticos, mientras que para los datos de texto o categoricos, querremos conocer la frecuencia de las distintas categorías.
Obtención de estadísticos
Disponemos de varios métodos para la obtención de estadísticos de un dataFrame. Lo más habitual es que empleemos el método describe() que proporciona un resumen de los datos estadísticos básicos. Logicamente, este método, sólo actua sobre los datos numéricos.
import seaborn as sns
df = sns.load_dataset('titanic')
print(df.describe())
Disponemos además de los siguientes métodos estadísticos que podemos aplicar a las distintas características:
count(): Conteo de valores nulos
min(), max(): Valor mínimo y máximo
sum(): Sumatorio
mean(): Valor medio
median(): Mediana
var(): Varianza
std(): Desviación estándar
cumsum(): Suma acumulada
hist(): Histograma
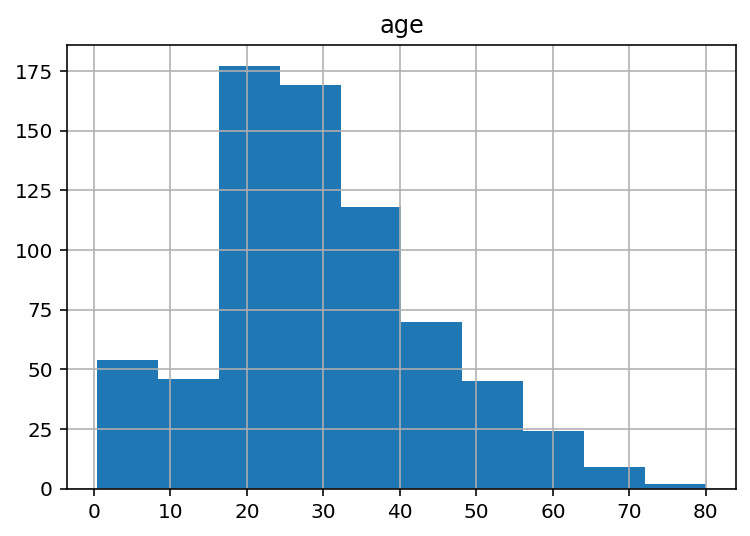
Por ejemplo, si quisieramos ver el histograma de la edad, podríamos emplear el siguiente código:
import seaborn as sns
df = sns.load_dataset('titanic')
print(df.hist('age'))
Y obtendríamos:
Histograma de la característica age
Frecuencias de datos categóricos
Para los datos no numéricos, la información que nos va a interesar será la frecuencia de las distintas categorías de cada característica. Si la característica en cuestión tiene muchas categorías, esta información tampoco va a aportar mucho. Sin embargo, cuando tengamos pocas categorías, esta información nos ayudará a entender la distribución de dichas categorías en nuestros datos, y saber por ejemplo si nuestro dataset está o no equilibrado con respecto a ese dato.
Spoiler: Cuando trabajemos con clasificadores en machine learning, tendremos que ver la distribución (frecuencia) de las categorías de la etiqueta(el valor que queramos predecir). Si nuestro dataset está desbalanceado, tendremos que hacer una división estratificada de nuestros datos, para asegurarnos que se mantienen las proporciones de las categorías en los dataset de entrenamiento y test.
Para conocer la frecuencia de cada una de las características podemos emplear el método value_counts(). Este método lo podemos aplicar tando a los campos numéricos como a los no numéricos, pero tendrá sentido cuando tengamos un conjunto de valores reducidos, de otra manera veremos muchas valores con frecuencias bajas, lo cual no aportará información.
Por ejemplo, si lo aplicamos a la característica ‘age’:
import seaborn as sns
df = sns.load_dataset('titanic')
print(df['age'].value_counts())
En este tema vamos a hablar de los dataframes en pandas, probablemente la estructura que más emplearemos. Un dataframe es asimilable a una tabla, es una estructura bidimensional de filas y columnas.
En la practica, cargaremos nuestros datos desde un fichero o una base de datos en un dataframe. Y esta será la estructura de datos que emplearemos en nuestros programas para trabajar con los datos. Cuando hallamos finalizado las operaciones que queramos con los datos, guardaremos el dataframe en algún sistema de persistencia de datos: un fichero o una base de datos.
Los objetos Series en pandas son arrays de una dimensión. Recuerda que en el post de introducción a pandas explicaba brevemente las tres estructuras de datos que provee esta libreria.
Creación de objetos Series
En pandas, vamos a poder crear los objetos Series de diversas maneras. En general, como se trata de arrays de una dimensión, tendremos que indicar los indices y los valores que se almacenan en dichos indices.
1.- Con una lista: Para crear un objeto Serie a partir de una lista, se pasa esta como parámetro a la función Series():
import pandas as pd
nombres=["Veronica","Pablo","Fabiola"]
listado = pd.Series(nombres)
print(listado)
Como en este caso sólo pasamos los valores, los indices los toma desde 0 a la longitud de la lista-1. El resultado de ejecutar el código anterior es:
0 Veronica
1 Pablo
2 Fabiola
dtype: object
2.- Con dos listas, una para los indices y otra para los valores. La primera se pasa en el parámetro index y la segunda en el parámetro data
import pandas as pd
nombres=["Veronica","Pablo","Fabiola"]
edades=[50,20,18]
se = pd.Series(index=nombres,data=edades)
print(se)
El resultado de ejecutar el código anterior es:
Veronica 50
Pablo 20
Fabiola 18
dtype: int64
3.- Con un diccionario: Se pasa el diccionario como parámetro a la función Series()
import pandas as pd
dicc={"Veronica":50,"Pablo":20,"Fabiola":18}
edades = pd.Series(dicc)
print(edades)
En este caso, se toman las claves del diccionario como indices, y los valores como valores del array. El resultado de ejecutar el programa anterior:
Veronica 50
Pablo 20
Fabiola 18
dtype: int64
4.- Con un array de Numpy: con un ndarray, más los indices:
import numpy as np
import pandas as pd
datos = np.array([50, 20, 18])
indice = ["Veronica", "Pablo", "Fabiola"]
edades = pd.Series(datos, index=indice)
print(edades)
Parámetros para crear un objeto Series
Los parámetros disponibles para crear un objeto Series son:
data: Los datos.
index: Los índices.
columns: Los nombres de las columnas. Si no se especifica, pandas intenta inferirlos.
dtype: Tipo de datos de las columnas.
copy: Si es True, se copia la estructura de datos en lugar de modificar el original.
Atributos de los objetos Series
Los principales atributos de los objetos Series de pandas:
index: Devuelve el índice de la Serie
values: Devuelve un array de NumPy con los valores de la Serie.
name: Nombre de la serie
dtype: Devuelve el tipo de datos
size: Número total de elementos en la Serie.
shape: Devuelve una tupla con el número de elementos.
empty: Indica si la serie está vacía
hasnans: Indica si la serie contiene valores NaN
En el código siguiente puedes ver como acceder a algunos atributos. Es como siempre, atraves del objeto y el nombre del atributo.
import pandas as pd
dicc={"Veronica":50,"Pablo":20,"Fabiola":18}
serie = pd.Series(dicc)
print("Índice:", serie.index)
print("Valores:", serie.values)
print("Nombre:", serie.name)
print("Tipo de datos:", serie.dtype)
print("Número de elementos:", serie.size)
print("¿Tiene datos?", not serie.empty)
El resultado de ejecución es:
Índice: Index(['Veronica', 'Pablo', 'Fabiola'], dtype='object')
Valores: [50 20 18]
Nombre: None
Tipo de datos: int64
Número de elementos: 3
¿Tiene datos? True
Métodos de los objetos Series
La colección de métodos de los objetos Series es bastante amplia. Algunos de los más habituales son:
head(n): Muestra las primeras n filas (valor por defecto: 5)
tail(n): Muestra las últimas n filas.
info(): Muestra información sobre el índice y el tipo de datos
describe(): Genera estadísticas descriptivas básicas
value_counts(): Cuenta las ocurrencias de cada valor en la Serie.
isna() / isnull(): Devuelve True si el valor es NaN.
notna() / notnull(): Devuelve True si el valor no es NaN.
dropna():Elimina los valores NaN de la Serie.
fillna(valor): Reemplaza valores NaN con un valor específico.
loc[]: Selección basada en etiquetas del índice.
iloc[]: Selección basada en posición numérica.
sum(): Suma de todos los valores.
mean(): Media aritmética.
median(): Mediana.
min() / max(): Valor mínimo y máximo.
En el código siguiente, puedes ver el uso de algunos de ellos.
import pandas as pd
dicc={"Veronica":50,"Pablo":20,"Fabiola":18}
serie = pd.Series(dicc)
serie.info()
print("Estadisticos de la serie\n",serie.describe())
print(f"Mediana de la serie: {serie.median()}")
El resultado:
<class 'pandas.core.series.Series'>
Index: 3 entries, Veronica to Fabiola
Series name: None
Non-Null Count Dtype
-------------- -----
3 non-null int64
dtypes: int64(1)
memory usage: 48.0+ bytes
Estadisticos de la serie
count 3.000000
mean 29.333333
std 17.925773
min 18.000000
25% 19.000000
50% 20.000000
75% 35.000000
max 50.000000
dtype: float64
Mediana de la serie: 20.0
Los métodos info() para obtener información general y describe() para obtener los estadísticos, los usaremos a todas horas. También con los DataFrames de pandas.
Principales operaciones con objetos Series
Trabajando con los elementos
Acceso por indice: La forma recomendada para acceder a un elemento de un objeto Series es a través de su índice empleando el método loc[] .
import pandas as pd
dicc={"Veronica":50,"Pablo":20,"Fabiola":18}
serie = pd.Series(dicc)
edad=serie.loc["Pablo"]
print(f"edad: {edad}")
El resultado:
edad: 20
Aunque también podemos acceder directamente a través del indice sin emplear el método loc(). Si bien se recomienda usar este método
edad=serie["Pablo"]
La sentencia de arriba da el mismo resultado que haciendolo a traves del método.
Acceso por posición: En este caso, empleamos el método iloc() al que pasamos como parámetro la posición, entendida con el índice numérico. Recordemos que los indices empiezan por cero, así que para acceder a la segunda posición pasaríamos el valor de 1.
import pandas as pd
dicc={"Veronica":50,"Pablo":20,"Fabiola":18}
serie = pd.Series(dicc)
edad=serie.iloc[1]
print(f"edad: {edad}")
edades=serie.iloc[:2]
print(f"edades:\n {edades}")
Podemos referenciar varias posiciones, siguiendo el criterio de selección de indices que empleabamos con las listas. El resultado de ejecución sería:
edad: 20
edades:
Veronica 50
Pablo 20
dtype: int64
Trabajando con los índices
Ya hemos visto que el parámetro index nos permite definir los indices del objeto Series. Así que podemos cambiar los indices a traves de este parámetro. Eso sí, hay que tener la precaución de definir todos los índices, si nuestra lista de índices tiene un número de valores distinto al número de indices del objeto Series, se producirá un error de Length mismatch: las longitudes de ambos no coinciden.
Aquí te dejo un ejemplo sencillito de la actualización de indices en un objeto Series
import pandas as pd
dicc={"Veronica":50,"Pablo":20,"Fabiola":18}
serie = pd.Series(dicc)
serie.index=["Francisco","Carmen","Rodrigo"]
print(serie)
El resultado de ejecución es:
Francisco 50
Carmen 20
Rodrigo 18
dtype: int64
No obstante, es extraño que queramos cambiar todos los indices, lo habitual sería que quisieramos cambiar unos pocos indices. En este caso, podemos usar el método rename(), como en el siguiente ejemplo:
import pandas as pd
dicc={"Veronica":50,"Pablo":20,"Fabiola":18}
serie = pd.Series(dicc)
serie.index=["Francisco","Carmen","Rodrigo"]
nueva_serie=serie.rename(index={"Francisco":"Paco"})
print(nueva_serie)
Nos generamos una serie nueva a partir de la serie con la que estabamos trabajando, cambiando los nombres de los indices que queramos. Para ello pasamos un diccionario con los cambios al método rename. Este diccionario tiene por claves los indices actuales y por valores los nuevos indices a los que queremos cambiar. De esta forma, sólo se actua sobre los indices que se quieran cambiar.
Filtrando datos
Otra de las operaciones habituales que tendremos que hacer sobre cualquier estructura de datos es buscar los datos que cumplan unas determinadas condiciones: realizar una consulta. Para ello, definiremos las condiciones que queramos empleando operadores lógicos. Por ejemplo:
import pandas as pd
import numpy as np
dicc={"Veronica":50,"Pablo":20,"Fabiola":17}
edades = pd.Series(dicc)
media_edad=np.mean(edades)
print(f"La media de edad es: {media_edad}")
mayor_edad=np.max(edades)
print(f"El mayor es: {mayor_edad}")
mayores = edades.index[edades.eq(mayor_edad)].to_list()
print(f"Los mayores son: {mayores}")
El resultado de ejecutar el código anterior es:
La media de edad es: 29.0
El mayor es: 50
Los mayores son: ['Veronica']
Nulos
Finalmente, tenemos que conocer también los métodos que provee pandas para lidiar con los nulos. Estos son los mismos que emplearemos más tarde para trabajar con los objetos DataFrame de pandas.
Los principales métodos para trabajar con nulos son:
isna(): Filtra los valores nulos.
notna(): Filtra los valores no nulos
dropna(): Elimina los valores nulos
fillna(): Remplaza los valores nulos por el valor que se pasa al método.
Por ejemplo, si quisieramos detectar los nulos de un objeto Series, empleamos isna():
import pandas as pd
dicc={"Veronica":50,"Pablo":20,"Fabiola":17,"Elena":None}
edades = pd.Series(dicc)
nulos=edades.isna()
print(f"nulos:\n{nulos}")
Este código nos da el resultado:
nulos:
Veronica False
Pablo False
Fabiola False
Elena True
dtype: bool
Y si ahora queremos sustituir los nulos por la media de la edad, usamos el método fillna():
import pandas as pd
dicc={"Veronica":50,"Pablo":20,"Fabiola":17,"Elena":None}
edades = pd.Series(dicc)
nulos=edades.isna()
print("nulos:\n------")
print(nulos)
edades_sin_nulos=edades.fillna(edades.mean())
print("edades sin nulos:\n-----------------")
print(edades_sin_nulos)
El resultado seria:
nulos:
------
Veronica False
Pablo False
Fabiola False
Elena True
dtype: bool
edades sin nulos:
-----------------
Veronica 50.0
Pablo 20.0
Fabiola 17.0
Elena 29.0
dtype: float64
NOTA:
Este post es parte de la colección “Python”. Puedes ver el índice de esta colección aquí.
Pandas es probablemente la libreria más popular entre los cientificos de datos para el trabajo y análisis con datos. En estas notas pretendo hacer una breve introducción a pandas que nos de una idea general de la libreria y como instalarla para poder empezar a usarla.
Es una iniciativa de código abierto y puedes ver su página oficial aquí.
En la página oficial vas a encontrar guías de usuarios super completas, pero al mismo tiempo es una documentación muy extensa, y a veces no es sencillo encontrar lo que uno busca. Siempre se puede recurrir también a la IA, aunque a mi modo de ver es mucho más útil para resolver dudas concretas cuando ya se tienen ciertos conocimientos.
Por ello, mi pretensión con estas notas de pandas, es hacer un recorrido sencillo sobre los fundamentos de esta libreria, para que el alumno pueda adquirir los fundamentos de la misma y empezar a usarla.
Pandas se construye sobre Numpy que es una libreria para calculo cientifico que trabaja con arrays. Si no has oido hablar de Numpy, echa primero un vistazo a esta página.
Estructuras de datos
Para trabajar con los datos, pandas provee tres estructuras de datos:
Series: Son arrays de una dimensión que se emplean habitualmente para trabajar con series temporales. Estos se parecen muchisimo a Numpy.
DataFrame: Esta es la madre del cordero, con los que trabajaremos a todas horas. Son estructuras de datos bidimensionales, tablas de datos que se organizan en filas y columnas. Cuando trabajemos con IA será la estructura en la que almacenemos los distintos datasets con los que entrenaremos y validaremos los modelos.
Panel: Son estructuras de datos de más de dos dimensiones. No son muy frecuentes y nosotros no vamos a usarlas.
Instalación
Pandas tiene algunas dependencias obligatorias de otras librerias, que tendremos que tenerlas instaladas antes de instalar pandas y poder trabajar con ella. En la práctica, tendremos que instalar numpy antes de instalar pandas, el resto de dependencias obligatorias vienen con la instalación habitual de python. Así que recuerda, instala numpy:
pip install numpy
Para saber si tienes instalado numpy puedes importar la libreria desde tu código. Ejecuta:
import numpy as np
Si no recibes ningún código de error es que la tienes instalada.
Instalación con pip
Para instalar pandas, disponemos de varias posibilidades. La más directa es usar el gestor de paquetes pip. Abre un terminal o línea de comandos y ejecuta la siguiente instrucción:
pip install pandas
Puedes encontrarte que necesites una versión concreta de pandas, por ejemplo si estás recuperando un proyecto y quieres asegurarte que pandas no tenga incompatibilidades entre las distintas librerias usadas en el proyecto, o si vas a usar una libreria que sólo funcione con una versión concreta de pandas. En cualquier caso, si necesitas instalar una versión concreta de pandas, indicala en la instrucción de instalación:
pip install pandas==2.0.3
Instalación en Jupyter Notebook
Si trabajas con Jupyter Notebook, puedes instalar pandas ejecutando el siguiente código:
!pip install pandas
Tenemos que usar el caracter de escape «!» como atajo para ejecutar comandos del sistema. Ten en cuenta que pip es un comando de consola.
Instalación en Anaconda
Anaconda es una suite que agrupa muchas utilidades para los cientificos de datos. A menudo se trabaja en este entorno, usando Anaconda Navigator para gestionar los entornos de los proyectos, instalando las librerias y herramientas que se necesiten para cada proyecto en su respectivo entorno.
Para instalar pandas en Anaconda empleamos la instrucción:
conda install pandas
Versión de pandas instalada
Finalmente, como comprobación de la instalación, y para asegurarnos de que hemos instalado la versión de pandas que queríamos, podemos ejecutar el siguiente código:
import pandas as pd
print(pd.__version__)
NOTA:
Este post es parte de la colección “Python”. Puedes ver el índice de esta colección aquí.
En este post, continuo con las notas de la libreria Numpy. Me centraré en las explicaciones de las operaciones con los arrays de Numpy. Si es tu primer contacto con Numpy, probablemente sea mejor que eches un vistazo al primer post de Numpy.
Modificación de un array
Empezamos creando un Array unidimensional inicializado con los valores 0-14
Podemos usar el método reshape para modificar las dimensiones de un array. Este método nos devuelve un nuevo Array que apunta a los mismos datos. Cualquier modificación en un array modificará también el otro.
El método devuelve un array sustituyendo los términos en los que se cumple la condición por el segundo parámetro y los que no cumplen la condición por el tercer parámetro. Tiene un funcionamiento similar a la función IF de Excel.
Numpy proporciona varios métodos para realizar cálculos estadísticos.
En el siguiente programa puede verse varios de estos métodos:
array = np.arange(1,21)
maximo=array.max() #Devuelve el valor máximo del array
minimo=array.min() #Devuelve el valor mínimo del array
media=array.mean() #Media de los elementos del array
suma=array.sum() #Suma de los elementos del array
desviacion_std=array.std() #Desviación estándar de los elementos del array
# Funciones universales eficientes proporcionadas por numpy: ufunc
cuadrado=np.square(array) #Cuadrado de los elementos del array
raiz=np.sqrt(array) #Raiz cuadrada de los elementos del array
exponencial=np.exp(array) #Exponencial de los elementos del array
logaritmo=np.log(array) #Logaritmos de los elementos del array
print(f"Array: \n {array}")
print(f"el elemento mayor del array es: {maximo}")
print(f"el elemento menor del array es: {minimo}")
print(f"la suma de los elementos del array es: {suma}")
print(f"la media de los elementos del array es: {media}")
print(f"la desviación estandard de los elementos del array es: {desviacion_std}")
print("ARRAYS")
print(f"El array con los elementos al cuadrado es: \n {cuadrado}")
print(f"El array con las raices cuadradas de los elementos es: \n {raiz}")
print(f"El array con el exponencial de los elementos es: \n {exponencial}")
print(f"El array con el logaritmo de los elementos es: \n {logaritmo}")
Resultado:
Array:
[ 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20]
el elemento mayor del array es: 20
el elemento menor del array es: 1
la suma de los elementos del array es: 210
la media de los elementos del array es: 10.5
la desviación estandard de los elementos del array es: 5.766281297335398
ARRAYS
El array con los elementos al cuadrado es:
[ 1 4 9 16 25 36 49 64 81 100 121 144 169 196 225 256 289 324
361 400]
El array con las raices cuadradas de los elementos es:
[1. 1.41421356 1.73205081 2. 2.23606798 2.44948974
2.64575131 2.82842712 3. 3.16227766 3.31662479 3.46410162
3.60555128 3.74165739 3.87298335 4. 4.12310563 4.24264069
4.35889894 4.47213595]
El array con el exponencial de los elementos es:
[2.71828183e+00 7.38905610e+00 2.00855369e+01 5.45981500e+01
1.48413159e+02 4.03428793e+02 1.09663316e+03 2.98095799e+03
8.10308393e+03 2.20264658e+04 5.98741417e+04 1.62754791e+05
4.42413392e+05 1.20260428e+06 3.26901737e+06 8.88611052e+06
2.41549528e+07 6.56599691e+07 1.78482301e+08 4.85165195e+08]
El array con el logaritmo de los elementos es:
[0. 0.69314718 1.09861229 1.38629436 1.60943791 1.79175947
1.94591015 2.07944154 2.19722458 2.30258509 2.39789527 2.48490665
2.56494936 2.63905733 2.7080502 2.77258872 2.83321334 2.89037176
2.94443898 2.99573227]
NOTA:
Este post es parte de la colección “Python”. Puedes ver el índice de esta colección aquí.
El paquete numpy es una librería fundamental para la computación científica con Python y es probable que ya lo tengamos instalado con la instalación de Python.
El nombre de Numpy viene de “Numerical Python”. Se trata de una potente librería para operar con arrays multidimiensionales y a menudo es empleada por otros paquetes como Pandas, SciPy (Scientific Python) y Matplotlib.
Las estructuras de almacenamiento de Numpy tienen algunos beneficios sobre las listas de Python y garantizan cálculos eficientes sobre vectores y matrices. Dispone de una extensa biblioteca de funciones matemáticas.
Proporciona arrays N-dimensionales
Implementa funciones matemáticas sofisticadas
Proporciona herramientas para integrar C/C++ y Fortran
Proporciona mecanismos para facilitar la realización de tareas relacionadas con álgebra lineal o números aleatorios
Instalando el paquete Numpy
Este paquete suele venir instalado con la versión de Python, por lo que normalmente probaremos a importarlo directamente, asumiendo que viene instalado. Si al importar la librería no hemos tenido ningún error, significará que ya lo tenemos instalado y no tenemos que hacer nada más.
Si no fuera así, y tuviéramos que instalarlo, podemos hacerlo escribiendo la siguiente instrucción en el interprete:
-m pip install - -user numpy
O si estamos usando el paquete anaconda, desde nuestro entorno activo, abrimos línea de comando y tecleamos:
pip install numpy
En cualquier caso, en la web de la librería se dispone de la información necesaria para instalarla en los distintos entornos que podamos tener.
Para importar la libreria a nuestro programa y poder empezar a usarla, empleamos la instrucción import:
import numpy as np
Normalmente utilizaremos como alias np
Array
Un array es una estructura de datos donde cada uno de ellos está identificado por un índice o un conjunto de ellos.
El tipo más simple de array es el array lineal, también conocido como array unidimensional donde cada elemento es identificado por un índice.
Un array puede tener varias dimensiones y cada elemento del array será identificado por un conjunto de índices, una para cada dimensión. Por ejemplo, una tabla equivale a un array de 2 dimensiones: fila y columna, donde para localizar a un elemento es necesario indicar los valores de ambos índices que identifican al elemento.
En numpy:
Las dimensiones se denominan axis
El número de dimensiones se denomina rank
La distintas dimensiones y sus longitudes se denominan shape
El número total de elementos (multiplicación de las longitudes de las dimensiones) se denomina size
Creando un array
Podemos crear el array introduciendo directamente sus valores
import numpy as np
array=np.array([1,"hola",3,4,5,6])
print(array)
Lo que arrojaría el resultado:
['1' 'hola' '3' '4' '5' '6']
También podemos crear un array indicando un rango de valores:
array=np.arange(7)
print(array)
El resultado obtenido es:
[0 1 2 3 4 5 6]
Hay que recordar que los rangos empiezan en cero y terminan en el número anterior al indicado, en este caso 7.
O crear un array introduciendo el primer valor, el último, y el salto entre valores
array=np.arange(1,12,3)
print(array)
Resultado:
[ 1 4 7 10]
Otro opción útil, es crear un array de ceros:
array_ceros = np.zeros((3, 4))
print(array_ceros)
Que da el resultado:
[[0. 0. 0. 0.]
[0. 0. 0. 0.]
[0. 0. 0. 0.]]
“array_ceros” es un array donde:
Tiene 2 axis (dimensiones: filas y columnas)
rank = 2 -> el número de dimensiones es 2
shape = (2, 4) -> la longitud de sus dimensiones es 2 y 4.
El argumento para el método array de numpy es una lista, por lo que si queremos construir un array multidimensional a partir de varias lista, tendremos que pasar a este método una lista de listas
En este post vamos a ver como trabajar con las bases de datos relacionales en Python. Para ello emplearemos SQLite que es Open Source y viene instalada por defecto con Python.
SQLite se presenta en un único fichero, como Access, y tiene por objetivo ser parte de la aplicación a la que proporciona los datos. Es decir, no cumple los conceptos de cliente y servidor como otros gestores de bases de datos relacionales como MySQL, SQLServer u Oracle. No obstante, para iniciarnos con las bases de datos relaciones en Python nos vale.
Conexión
Lo primero que tenemos que hacer es establecer una conexión a la base de datos. En el ejemplo que nos ocupa, con SQLite, es bastante sencillo. Utilizamos el método connect al que pasamos como parámetro la ruta de la base de datos.
import sqlite3
import os
#Establezco el directorio de trabajo
os.chdir("c:\Python")
#Abro conexion con la BBDD, si no existe la crea
conexion = sqlite3.connect("Pedidos.db")
conexion.close()
Para simplificar y no tener que ir introduciendo la ruta cada vez que me conecte a la BBDD, defino como directorio de trabajo la carpeta en la que tengo el script de python y la BBDD. Si existe la BBDD nos la abrirá, si no existe, la crea.
Una vez creada la conexión, podemos utilizar el método execute para ejecutar instrucciones SQL sobre la BBDD a la que nos hemos conectado. Vamos a verlo para las distintas operaciones básicas.
Definición de la estructura de la base de datos
En este apartado vamos a ver las operaciones SQL básicas para definir la estructura de nuestra base de datos. Estas serán todas aquellas que nos permitan crear, eliminar o modificar, las distintas tablas e índices de la base de datos.
Estructura de la base de datos
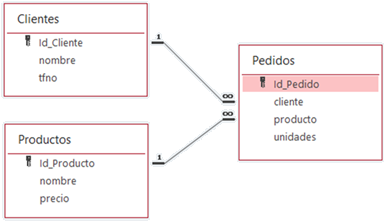
Para practicar las principales operaciones que podemos realizar con una base de datos relacional, vamos a diseñarnos una BBDD muy sencilla.
Esta base de datos va a guardar los pedidos de los clientes de una frutería. Tendremos tres tablas:
Productos
Clientes
Pedidos
La estructura de nuestra BBDD es la siguiente:
Estructura de la base de datos
Para asegurar la robustez de la base de datos, defino claves únicas en cada tabla que serán las que emplee para establecer las relaciones.
Creación de una tabla
Empezamos creando las tablas, para lo que tenemos varias opciones.
1.- Utilizando un bloque try-except: pasamos al método execute la correspondiente instrucción SQL.
conexion = sqlite3.connect("Pedidos.db")
try:
conexion.execute("""create table Productos (
Id_Producto integer primary key AUTOINCREMENT,
nombre text,precio real)""")
print("se creo la tabla Productos")
except sqlite3.OperationalError:
print("la tabla Productos ya existe")
conexion.close()
2.- Otra manera de crear una tabla sin tener que manejar excepciones.
conexion = sqlite3.connect("Pedidos.db")
conexion.execute("""create table if not exists Clientes(
Id_Cliente integer primary key AUTOINCREMENT,
nombre text, tfno text )""")
print("se creo la tabla Clientes")
conexion.close()
3.- Y vamos a crear una tercera tabla: pedidos, que registre el producto, el cliente y las unidades de producto en el pedido. En este caso vamos a definir una clave primaria que se incremente automáticamente cada vez que se añada un pedido
conexion = sqlite3.connect("Pedidos.db")
conexion.execute("""create table if not exists Pedidos(
Id_Pedido integer primary key AUTOINCREMENT,
cliente integer,
producto integer,
unidades integer)""")
print("se creo la tabla Pedidos")
conexion.close()
Para comprobar si hemos creado las tablas correctamente, podemos usar el siguiente código que hace un select en la tabla especial sqlite_master, donde se almacena información de la estructura de la base de datos.
conexion = sqlite3.connect("Pedidos.db")
# Crea un cursor
cursor = conexion.cursor()
# Ejecuta la consulta para obtener las tablas
cursor.execute("SELECT name FROM sqlite_master WHERE type='table';")
# Recorre los resultados e imprime los nombres de las tablas
print("Tablas en la base de datos:")
print("----------------------------")
for tabla in cursor.fetchall():
print(tabla[0])
# Cierra la conexión
conexion.close()
El resultado sería:
Tablas en la base de datos:
----------------------------
Productos
sqlite_sequence
Clientes
Pedidos
Vemos que nos aparece una tabla que no hemos creado, la tabla sqlite_sequence. SQLite la crea automáticamente y la utiliza para mantener un seguimiento de los valores de las claves primarias autoincrementales, asegurando que cada vez que se inserta un nuevo registro en una tabla con una columna de clave primaria autoincremental, el valor de esa columna se incremente correctamente.
Eliminación de una tabla
Para eliminar una tabla, tendremos que utilizar la sentencia SQL: DROP TABLE.
Con el siguiente código eliminaríamos la tabla “Clientes”
conexion = sqlite3.connect("Pedidos.db")
# Crear un cursor para ejecutar comandos SQL
cursor = conexion.cursor()
# Ejecutar la sentencia SQL para eliminar la tabla
tabla_a_eliminar="Clientes"
cursor.execute(f'DROP TABLE IF EXISTS {tabla_a_eliminar};')
# Confirmar los cambios
conexion.commit()
# Cerrar la conexión
conexion.close()
La cláusula IF EXISTS asegura que no se genere un error si la tabla no existe.
Tenemos que confirmar los cambios con conexion.commit() después de ejecutar la sentencia SQL y cerrar la conexión al final.
Si ahora, volvemos a comprobar las tablas que tiene nuestra base de datos, el resultado sería el siguiente:
Tablas en la base de datos:
----------------------------
Productos
sqlite_sequence
Pedidos
Y volvemos a generar la tabla Clientes para dejar la base de datos completa, tal y como la diseñamos.
Creación de un índice
Para crear un índice en una tabla, usamos la sentencia SQL: CREATE INDEX
Con el código siguiente se crearía un índice de nombre: “id_tfno” asociado al campo “tfno” de la tabla “Clientes”
conexion = sqlite3.connect("Pedidos.db")
# Crear un cursor para ejecutar comandos SQL
cursor = conexion.cursor()
# Sentencia SQL para crear un indice en el campo "tfno" de la tabla "Clientes"
sentencia_sql=""" CREATE INDEX IF NOT EXISTS id_tfno ON Clientes (tfno);"""
# Ejecutar la sentencia SQL para crear el índice
cursor.execute(sentencia_sql)
# Confirmar los cambios
conexion.commit()
# Cerrar la conexión
conexion.close()
Con la cláusula IF NOT EXISTS nos aseguramos que el índice solo se cree si no existe ya en la base de datos, evitando posibles errores por ejecutar el script varias veces.
Siempre hay que confirmar los cambios con conexion.commit() después de ejecutar la sentencia SQL y cerrar la conexión cuando terminamos.
Para verificar que el índice se ha generado correctamente, consultamos el esquema de la base de datos para ver si el índice está presente.
conexion = sqlite3.connect("Pedidos.db")
# Crear un cursor para ejecutar comandos SQL
cursor = conexion.cursor()
# Obtener información sobre los índices de la tabla 'Clientes'
tabla = "Clientes"
cursor.execute(f"PRAGMA index_list({tabla});")
indices = cursor.fetchall()
# Verificar si el índice que hemos creado está en la lista de índices
nombre_indice = 'id_tfno'
if any(nombre_indice in index for index in indices):
print(f"El índice {nombre_indice} está presente en la tabla {tabla}.")
else:
print(f"El índice {nombre_indice} no está presente en la tabla {tabla}.")
# Cerrar la conexión
conexion.close()
En nuestro caso, la ejecución del código anterior nos daría el resultado:
El índice id_tfno está presente en la tabla Clientes.
Eliminación de un índice
Y para eliminar un índice, usamos la sentencia SQL: DROP INDEX.
Por ejemplo, para eliminar el índice “id_tfno” que creamos en el apartado anterior, usaríamos el siguiente código:
conexion = sqlite3.connect("Pedidos.db")
# Crear un cursor para ejecutar comandos SQL
cursor = conexion.cursor()
# Nombre del índice a eliminar
nombre_indice = 'id_tfno'
# Sentencia SQL para eliminar el índice
sentencia_sql = f"DROP INDEX IF EXISTS {nombre_indice};"
# Ejecutar la sentencia SQL para eliminar el índice
cursor.execute(sentencia_sql)
# Confirmar los cambios
conexion.commit()
# Cerrar la conexión
conexion.close()
Si ejecutamos de nuevo el código para comprobar si existe el índice “id_tfno” en la tabla Clientes, el resultado sería:
El índice id_tfno no está presente en la tabla Clientes.
Modificación de la estructura de una tabla
Una vez generada la estructura, puede darse la situación de que queramos cambiar parte de esa estructura. Podemos querer cambiar el tipo de dato de un campo, añadir un campo nuevo a una tabla u otro tipo de operaciones que modifican la estructura. En general, todas aquellas operaciones que en SQL hacemos con la sentencia: ALTER TABLE.
Supongamos que en nuestro caso, queremos añadir el campo “email” a la tabla “Clientes”. Podríamos hacerlo con el siguiente código:
conexion = sqlite3.connect("Pedidos.db")
# Crear un cursor para ejecutar comandos SQL
cursor = conexion.cursor()
# Sentencia SQL para agregar el campo 'email' a la tabla 'Clientes'
sentencia_sql = """
ALTER TABLE Clientes
ADD COLUMN email TEXT;"""
# Ejecutar la sentencia SQL para agregar el campo 'email'
cursor.execute(sentencia_sql)
# Confirmar los cambios
conexion.commit()
# Cerrar la conexión
conexion.close()
Imagino que a estas alturas ya se aprecia que el proceso siempre es el mismo, y sigue los siguientes pasos:
Nos conectamos a la base de datos.
Generamos un cursor que apunta a la base de datos y que emplearemos para ejecutar las sentencias SQL.
Usando el cursor, ejecutamos la sentencia SQL que queramos, empleando el método execute del cursor.
Confirmamos los cambios con el método commit.
Y cerramos la conexión con el método close.
Para comprobar que hemos creado bien el campo “email” en la tabla “Clientes”, podemos ejecutar el siguiente código que nos mostrara la estructura de la tabla “Clientes”
conexion = sqlite3.connect("Pedidos.db")
# Crear un cursor para ejecutar comandos SQL
cursor = conexion.cursor()
# Nombre de la tabla
tabla = 'Clientes'
# Consulta SQL para obtener la estructura de la tabla
consulta_sql = f"PRAGMA table_info({tabla});"
# Ejecutar la consulta SQL
cursor.execute(consulta_sql)
# Obtener los resultados de la consulta
estructura_tabla = cursor.fetchall()
# Imprimir la estructura de la tabla
print("Estructura de la tabla", tabla)
print("----------------------------")
for columna in estructura_tabla:
nombre_columna = columna[1]
tipo_dato = columna[2]
print(f"Nombre: {nombre_columna}, Tipo de dato: {tipo_dato}")
# Cerrar la conexión
conexion.close()
La sentencia PRAGMA en SQLite es una forma de acceder y modificar parámetros específicos del motor de base de datos SQLite, así como obtener información sobre la base de datos, tablas, índices, entre otros. Es importante destacar que PRAGMA no es parte del estándar SQL y su comportamiento puede variar entre diferentes sistemas de gestión de bases de datos.
Si ejecutamos el código anterior, el resultado sería:
Estructura de la tabla Clientes
----------------------------
Nombre: Id_Cliente, Tipo de dato: INTEGER
Nombre: nombre, Tipo de dato: TEXT
Nombre: tfno, Tipo de dato: TEXT
Nombre: email, Tipo de dato: TEXT
Manipulación de datos
Dentro de este apartado, incluyo todas las operaciones para añadir, eliminar o modificar, los datos de las distintas tablas de nuestra base de datos.
Añadir datos
Damos por finalizado el trabajo con la estructura de la base de datos, y ahora comenzamos a trabajar directamente con los datos.
Lo primero que tendremos que hacer será introducir algunos datos, lo que hacíamos en SQL con la sentencia: INSERT INTO.
Por ejemplo, si quisiéramos introducir en la Tabla productos los datos de la siguiente tabla:
Nombre
Precio
Manzana
2
Pera
3
Aguacate
7
Tendríamos que usar el siguiente código:
conexion = sqlite3.connect("Pedidos.db")
conexion.execute("insert into Productos (nombre,precio) values (?,?)",("Manzana",2))
conexion.execute("insert into Productos (nombre,precio) values (?,?)",("Pera",3))
conexion.execute("insert into Productos (nombre,precio) values (?,?)",("Aguacate",7))
conexion.commit()
conexion.close()
Voy a adelantar ahora un código sencillo para recuperar los datos de una tabla y de esta forma poder comprobar que se han añadido los datos anteriores. Sería una consulta SELECT de todos los campos, sin ninguna condición, con lo que recuperamos todos los registros. El código sería:
conexion = sqlite3.connect("Pedidos.db")
cursor=conexion.execute("select * from Productos")
for fila in cursor:
print(fila)
conexion.close()
Donde podemos observar que el campo: “Id_Producto”, se ha rellenado automáticamente por SQLite, como era de esperar, ya que este era un campo Autonumérico.
Actualizar datos
Otra operación muy habitual que realizar con los datos es la operación de actualización de valores que se realiza con la sentencia SQL: UPDATE
Supongamos que al introducir el precio del aguacate nos equivocamos y que su verdadero precio es 5. El código para actualizar el dato sería.
conexion = sqlite3.connect("Pedidos.db")
cursor = conexion.cursor()
nuevo_valor= 5
fruta="Aguacate"
cursor.execute("UPDATE Productos SET precio = ? WHERE nombre = ?",
(nuevo_valor,fruta))
conexion.commit()
conexion.close()
Si volvemos a ejecutar la consulta de selección para recuperar todos los registros de la tabla Productos, obtendríamos el siguiente resultado:
Para borrar datos empleamos la sentencia SQL: DELETE
El código siguiente te muestra un ejemplo de como utilizarla
conexion = sqlite3.connect("Pedidos.db")
cursor = conexion.cursor()
fruta="Aguacate"
cursor.execute("DELETE FROM Productos WHERE nombre = ?",(fruta,))
conexion.commit()
conexion.close()
Si volvemos a ejecutar la consulta de selección para recuperar todos los registros de la tabla Productos, obtendríamos el siguiente resultado:
(1, 'Manzana', 2.0)
(2, 'Pera', 3.0)
Recuperar datos
Finalmente, tenemos las famosas consultas SELECT para recuperar datos.
Recuerdo rápidamente en este punto la sintaxis de la sentencia SQL:
SELECT [ALL | DISTINCT] <lista de campos> FROM <lista de tablas>
[WHERE ….]
[GROUP BY…]
[HAVING….]
[ORDER BY…]
No obstante, para poder practicar con esta sentencia, tenemos que introducir más datos en nuestra base de datos. Ejecuta el siguiente código para añadir más datos a todas las tablas:
conexion = sqlite3.connect("Pedidos.db")
#rellenamos la tabla Producto
conexion.execute("insert into Productos (nombre,precio) values (?,?)",("Limon",2.5))
conexion.execute("insert into Productos (nombre,precio) values (?,?)",("Melocoton",3.7))
conexion.execute("insert into Productos (nombre,precio) values (?,?)",("Naranja",4))
#llenamos la tabla Clientes
conexion.execute("insert into Clientes (nombre,tfno,email) values (?,?,?)",("Pepe","123456789","pepe@gm.es"))
conexion.execute("insert into Clientes (nombre,tfno,email) values (?,?,?)",("Maria","234567890","maria@gm.es"))
conexion.execute("insert into Clientes (nombre,tfno,email) values (?,?,?)",("Elena","345678901","elena@gm.es"))
#llenamos la tabla Pedidos
conexion.execute("insert into Pedidos (cliente,producto,unidades) values (?,?,?)",(1,2,5))
conexion.execute("insert into Pedidos (cliente,producto,unidades) values (?,?,?)",(1,1,3))
conexion.execute("insert into Pedidos (cliente,producto,unidades) values (?,?,?)",(1,5,1))
conexion.execute("insert into Pedidos (cliente,producto,unidades) values (?,?,?)",(2,4,3))
conexion.execute("insert into Pedidos (cliente,producto,unidades) values (?,?,?)",(2,5,3))
conexion.execute("insert into Pedidos (cliente,producto,unidades) values (?,?,?)",(2,6,2))
conexion.execute("insert into Pedidos (cliente,producto,unidades) values (?,?,?)",(3,2,7))
conexion.execute("insert into Pedidos (cliente,producto,unidades) values (?,?,?)",(3,5,2))
conexion.execute("insert into Pedidos (cliente,producto,unidades) values (?,?,?)",(3,4,2))
conexion.commit()
conexion.close()
Recuerda que podemos ver los registros de una tabla con el código siguiente, actualizando el nombre de la tabla
tabla="Clientes"
print(f"Registros tabla: {tabla}")
conexion = sqlite3.connect("Pedidos.db")
cursor=conexion.execute(f"select * from {tabla}")
for fila in cursor:
print(fila)
conexion.close()
Si lo hemos hecho todo según lo indicado, los contenidos de nuestras tablas serían:
Ahora que tenemos algunos datos en nuestra base de datos, vamos a ver cómo realizar las consultas SELECT más habituales
Seleccionar todos los datos de una tabla
Imaginemos que queremos recuperar todos los datos de la tabla Clientes. La sentencia SQL para realizar esa operación sería:
SELECT * FROM nombre_de_la_tabla;
Y un código para ejecutar esta consulta y presentar los resultados:
#Recuperar todos los registros de una tabla -> SELECT
tabla="Clientes"
print(f"Registros tabla: {tabla}")
# nos conectamos a la base de datos
conexion = sqlite3.connect("Pedidos.db")
# ejecutamos la consulta
cursor=conexion.execute(f"select * from {tabla}")
# pintamos el resultado de la consulta, fila a fila
for fila in cursor:
print(fila)
# cerramos la conexión con la base de datos
conexion.close()
Donde puede observarse que he duplicado los registros. Ojo, hay que tener en cuenta que el primer campo: “Id_Cliente” es autonumérico, generado automáticamente por la BBDD cuando insertamos un dato nuevo. Por tanto, si consideramos este campo, nunca tendríamos duplicados. En nuestra consulta consideraremos todos los campos salvo “Id_Cliente”
Teclea el código:
#Recuperar todos los registros únicos de una tabla con la clausula DISTINCT
tabla="Clientes"
print(f"Registros tabla: {tabla}")
conexion = sqlite3.connect("Pedidos.db")
cursor=conexion.execute(f"select DISTINCT nombre,tfno,email from {tabla}")
for fila in cursor:
print(fila)
conexion.close()
Lógicamente nos salen duplicados ya que tenemos duplicados en la tabla Clientes. Si quisiéramos obtener resultados únicos, bastaría con añadir la clausula DISTINCT a la consulta.
Seleccionar registros que cumplan una condición
La sentencia SQL para realizar esa operación sería:
SELECT * FROM nombre_de_la_tabla WHERE condicion;
Ahora paso a utilizar la tabla productos, que tenía los valores
Imaginemos que queremos seleccionar todos aquellos productos que tengan un precio inferior a un valor que introduzca el usuario. Podríamos usar el código siguiente:
max_precio=int(input("Introduce el precio maximo\n"))
conexion = sqlite3.connect("Pedidos.db")
cursor=conexion.execute(f"select * from Productos WHERE precio<{max_precio}")
for fila in cursor:
print(fila)
conexion.close()
Y el resultado obtenido, si por ejemplo el usuario introduce 3 como precio máximo, sería:
Supongamos que queremos extraer solamente la información de la Manzana. Podríamos hacerlo con cualquiera de las dos sentencias siguientes:
cursor=conexion.execute("select * from Productos where nombre='Manzana' ")
cursor=conexion.execute("""select * from Productos where nombre="Manzana" """)
Si para el argumento del método execute empleamos triple comilla doble, podremos utilizar las comillas dobles para establecer condiciones con textos. Si preferimos usar una comilla doble, tendremos que usar comilla simple para establecer las condiciones con textos.
Por otro lado, la triple comilla doble te permite partir la sentencia SQL en varias líneas, lo cual la hace más fácil del leer.
Ordenar los resultados
Si queremos ordenar los resultados en orden ascendente, la sentencia SQL para realizar esa operación sería:
SELECT * FROM nombre_de_la_tabla ORDER BY columna ASC;
Y si fuera en orden descendente:
SELECT * FROM nombre_de_la_tabla ORDER BY columna DESC;
Con el siguiente código, obtenemos dos consultas: los productos ordenados por precio en orden ascendente y en orden descendente:
# Ordenando ascendente por precio
print("Consulta ordenada por precio ascendente")
conexion = sqlite3.connect("Pedidos.db")
cursor=conexion.execute("select * from Productos order by precio ASC")
for fila in cursor:
print(fila)
conexion.close()
# Ordenando ascendente por precio
print("Consulta ordenada por precio descendente")
conexion = sqlite3.connect("Pedidos.db")
cursor=conexion.execute("select * from Productos order by precio DESC")
for fila in cursor:
print(fila)
conexion.close()
El resultado de ejecutar el código anterior sería:
Combinar múltiples condiciones con operadores lógicos
La sentencia SQL para realizar esa operación sería:
SELECT * FROM nombre_de_la_tabla WHERE condicion1 AND/OR condicion2;
Por ejemplo:
conexion = sqlite3.connect("Pedidos.db")
cursor=conexion.execute("select * from Productos where nombre='Manzana' AND precio<5 ")
for fila in cursor:
print(fila)
conexion.close()
Nos dará el resultado:
(1, 'Manzana', 2.0)
Cálculos con los datos de un campo
Existen varias funciones que se pueden aplicar a un campo, que devuelven distintos cálculos realizados con los datos del campo. Por ejemplo, si quisiéramos obtener el máximo de los valores del campo, tenemos la función MAX(campo). Si fuera el mínimo, la función MIN(campo).
Las sentencias SQL para realizar las operaciones más habituales son:
1.- Máximo de los valores de un campo
SELECT MAX(campo) FROM nombre_de_la_tabla;
2.- Mínimo de los valores de un campo
SELECT MIN(campo) FROM nombre_de_la_tabla;
3.- Suma de los valores de un campo
SELECT SUM(campo) FROM nombre_de_la_tabla;
4.- Promedio de los valores de un campo
SELECT AVG(campo) FROM nombre_de_la_tabla;
Para practicar con estas funciones, prueba el código siguiente:
# Calculo el máximo
conexion = sqlite3.connect("Pedidos.db")
cursor=conexion.execute("select max(precio) from Productos")
resultado = cursor.fetchone()
print(f"precio máximo: {resultado[0]}")
conexion.close()
# Calculo el mínimo
conexion = sqlite3.connect("Pedidos.db")
cursor=conexion.execute("select min(precio) from Productos")
resultado = cursor.fetchone()
print(f"precio mínimo: {resultado[0]}")
conexion.close()
# Calculo el precio medio
conexion = sqlite3.connect("Pedidos.db")
cursor=conexion.execute("select avg(precio) from Productos")
resultado = cursor.fetchone()
print(f"precio medio: {resultado[0]}")
conexion.close()
En no pocas ocasiones, necesitaremos cruzar los datos de nuestras tablas. La sentencia SQL que nos permite hacer esto es:
SELECT tabla1.columna, tabla2.columna FROM tabla1 JOIN tabla2 ON tabla1.columna_comun = tabla2.columna_comun;
Cuando trabajemos con este tipo de consultas en las que manejamos varias tablas, tenemos que tener muy presente la estructura de la BBDD. Recupero en este punto la estructura de la nuestra:
Estructura de nuestra base de datos
Supongamos que queremos obtener para cada producto del que tenemos un pedido, su precio y las unidades vendidas. Además, queremos que se nos muestre en la consulta el nombre del producto. Así pues, seleccionaremos los campos “nombre” y “precio” de la tabla “Productos” y el campo “unidades” de la tabla “Pedidos”.
El código sería:
conexion = sqlite3.connect("Pedidos.db")
cursor=conexion.execute("""
select Productos.nombre, Productos.precio, Pedidos.unidades
from Productos
join Pedidos on Productos.Id_Producto=Pedidos.producto
""")
for fila in cursor:
print(fila)
conexion.close()
Si queremos extender la consulta y añadir la información del cliente, pero queremos el nombre del Cliente y no el identificador que aparece en Pedidos, tendremos que involucrar la tabla “Clientes” en la consulta, y habrá que especificar la relación de esta con la tabla “Pedidos”. Además, vamos a aprovechar y recuperamos también el email del Cliente.
El código a ejecutar sería:
conexion = sqlite3.connect("Pedidos.db")
cursor=conexion.execute("""
select Clientes.nombre, Clientes.email, Productos.nombre,
Productos.precio, Pedidos.unidades
from Productos
join Pedidos on Productos.Id_Producto=Pedidos.producto
join Clientes on Clientes.Id_Cliente=Pedidos.cliente
""")
for fila in cursor:
print(fila)
conexion.close()
El resultado de la ejecución del código anterior es:
Para agrupar los datos en las consultas, disponemos de la clausula GROUP BY.
Supongamos que para la consulta en la que teníamos todos los pedidos de los productos con su nombre, precio y unidades, queremos agrupar los resultado por nombre y precio, y en las columnas presentar el total de las unidades para cada pedidas para cada producto.
Un código que implementaría esa consulta es:
conexion = sqlite3.connect("Pedidos.db")
cursor=conexion.execute("""
select Productos.nombre, Productos.precio,
SUM(Pedidos.unidades) as unidades_totales
from Productos
join Pedidos on Productos.Id_Producto=Pedidos.producto
group by Productos.nombre,Productos.precio
""")
for fila in cursor:
print(fila)
conexion.close()
Puede observarse que se usa la función SUM para indicar que en esa columna de la consulta presentamos la suma de las unidades pedidas, además hemos definido el nombre de esa columna en la consulta como: “unidades_totales”. Luego, con la clausula GROUP BY, indicamos porque campos queremos agrupar los resultados de la consulta.
Para apreciar el resultado de la consulta, te muestro los datos agrupados que genera esta consulta, frente a los mismos datos sin agrupar:
Acceder a los valores de los campos de los resultados de una consulta
Los resultados de una consulta se entregan en forma de una lista de filas. Cada fila se correspondería con una línea de la consulta. Hasta ahora hemos venido recuperando las líneas de la consulta una a una, recorriendo la consulta con un bucle for. Por ejemplo, con el código:
conexion = sqlite3.connect("Pedidos.db")
cursor=conexion.execute("select * from Productos")
for fila in cursor:
print(fila)
conexion.close()
Cada línea del resultado de la consulta es una tupla que contiene los valores de los campos de esa fila. Por tanto, si queremos recuperar el valor de un campo concreto de una de esas líneas, accederemos a él como accederíamos a los valores de cualquier tupla, utilizando la indexación de la tupla.
Supongamos que queremos ver únicamente los productos y sus precios. Obviamente podríamos hacerlo directamente con una consulta que sólo nos devolviera esos campos, o podemos extraerlos de una consulta más general. Prueba el siguiente código para la segunda opción:
#pinto todas las lineas
conexion = sqlite3.connect("Pedidos.db")
cursor=conexion.execute("select * from Productos")
print("primero presento la consulta pintando todas las lineas")
for fila in cursor:
print(fila)
conexion.close()
#pinto los campos que me interesan
conexion = sqlite3.connect("Pedidos.db")
cursor=conexion.execute("select * from Productos")
print("ahora pinto solo los campos que me interesan")
for fila in cursor:
print(f” {fila[1]} : {fila[2]} €")
conexion.close()
Si lo ejecutas, obtendrás el resultado:
primero presento la consulta pintando todas las lineas
(1, 'Manzana', 2.0)
(2, 'Pera', 3.0)
(4, 'Limon', 2.5)
(5, 'Melocoton', 3.7)
(6, 'Naranja', 4.0)
ahora pinto solo los campos que me interesan
Manzana : 2.0 €
Pera : 3.0 €
Limon : 2.5 €
Melocoton : 3.7 €
Naranja : 4.0 €
NOTA:
Este post es parte de la colección “Python”. Puedes ver el índice de esta colección aquí.
Es muy habitual trabajar con ficheros de texto en Python. Los utilizaremos como sistema de persistencia de datos, para guardar datos y para recuperarlos luego.
En este post vamos a ver cómo realizar las funciones básicas con ficheros de texto: leer, escribir y añadir datos.
Abrir un fichero de texto
Lo primero que tenemos que hacer para trabajar con un fichero de texto es abrirlo y cargar sus datos. La función open() abre un archivo y devuelve un objeto para leer y escribir en el fichero.
El parámetro modo_apertura presenta los siguientes valores posibles:
‘r’: Solo lectura (valor por defecto)
‘w’: Solo escritura (en caso de que ya exista, lo borra).
‘a’: Appending. Escritura al final del fichero.
‘r+’: Para lectura y escritura
Te recomiendo que en el parámetro encoding lo pases con el valor «utf-8». Con esa codificación te aseguras que lees bien las eñes y las tildes.
fichero = open("Suppliers.txt",'r',encoding="utf-8")
for line in f:
print(line)
f.close()
En el código de arriba, abrimos el fichero en modo lectura, lo leemos con un bucle for línea a línea, lo imprimimos y cuando hemos acabado lo cerramos
Después de cargar los datos del fichero, tenemos que cerrarlo con el metodo close()
El modo recomendado para abrir un fichero de texto es usar with open(). La ventaja de este método es que no tenemos que preocuparnos de cerrar el fichero, la sentencia with lo hace cuando acaba de trabajar con él.
with open("Suppliers.txt") as file_object:
contenido=file_object.read()
print (contenido)
Hay que tener en cuenta que dejar un fichero sin cerrar después de trabajar con él puede ocasionar problemas serios, pudiéndose llegar a perder los datos almacenados en el mismo.
Leer un fichero de texto
Una vez hemos abierto un fichero de texto y tenemos su información en un objeto, podemos leer los datos de diversas maneras. Por ejemplo: carácter a carácter:
with open("Suppliers.txt") as file_object:
contenido=file_object.read()
for caracter in contenido:
print(carácter,end=””)
En el código anterior, con el método read() cargamos todo el texto del fichero en contenido y luego lo recorremos caracter a caracter con el bucle for. Aquí, al usar with open() no hay que preocuparse de cerrar el fichero, Python lo hace automaticamente cuando acaba de cargar los datos en contenido.
También podemos recorrer el fichero línea a línea con un bucle for:
with open("Suppliers.txt") as file_object:
for linea in file_object:
print(linea)
En este caso, permanecemos con el fichero abierto trabajando línea a línea, pintandolas por pantalla. Si el tamaño del fichero es muy grande es posible que nos veamos forzados a trabajar de este modo, ya que no tendríamos la posibilidad de guardar todo el fichero en una variable como el caso anterior, cuando leiamos caracter a caracter.
También podemos leer las líneas de un fichero directamente con el método readlines() y crearnos una lista con las líneas. Si el fichero es muy grande, podría causar problemas al intentar guardar todos los datos en una lista.
with open("Suppliers.txt") as file_object:
lineas = file_object.readlines()
for linea in lineas:
print(linea)
Escribir en un fichero de texto
Para escribir en un fichero de texto nuevo, usamos with open y el método write. Un ejemplo sería:
fichero="Planetas.txt"
with open(fichero,"w") as objetoFichero:
objetoFichero.write("Jupiter\n")
objetoFichero.write("Neptuno\n")
objetoFichero.write("Saturno\n")
De nuevo, aquí tenemos la ventaja de que con with open no hay que preocuparse de cerrar el fichero, Python lo hace automáticamente cuando acaba de trabajar con él.
Si lo que queremos es añadir datos a un fichero ya existente, sencillamente tendríamos que abrirlo con el método de apertura: «a»
fichero="Planetas.txt"
with open(fichero,"a") as objetoFichero:
objetoFichero.write("Mercurio\n")
objetoFichero.write("Venus\n")
NOTA:
Este post es parte de la colección “Python”. Puedes ver el índice de esta colección aquí.
Para manejar los errores de entorno, que no dependen del programador, sino que los genera el usuario, vamos a emplear las excepciones. Las excepciones en Python son eventos que interrumpen el flujo normal de un programa cuando ocurre un error (por ejemplo, dividir entre cero o intentar acceder a un fichero que no existe o que no está localizado en la carpeta en la que lo estamos buscando). En lugar de dejar que el programa falle sin control, Python permite capturar y manejar estas situaciones con bloques try-except, y complementar el control con else y finally para ejecutar código cuando no hay errores o siempre, respectivamente. También es posible lanzar errores de forma explícita con raise y definir excepciones propias para representar problemas específicos de tu aplicación.
Bloque try-except
En el bloque try pondremos las instrucciones que pueden generar la excepción y en el bloque except las instrucciones para gestionar dicha excepción en el caso que se produzca.
Ejemplo:
fichero="Planetas.txt"
try:
with open(fichero) as objetoFichero:
contenido=objetoFichero.read()
except FileNotFoundError:
print("Ufff, parece que el fichero ",fichero," no existe")
print(contenido)
Se pueden capturar distintos tipos de excepciones con múltiples except. Hay que colocar primero las excepciones más específicas y al final las más genéricas, ya que las clausulas except se evalúan en orden, y cuando coincide se ejecuta y no se evalúan más clausula except.
fichero = "planetas.txt"
try:
with open(fichero) as fh:
contenido = fh.read()
except FileNotFoundError as e:
print(f"No se encuentra el fichero: {e.filename}")
except PermissionError:
print("No tienes permisos para abrir el fichero.")
except OSError as e:
print(f"Otro error de E/S: {e}")
except Exception as e:
print(f"Error inesperado: {type(e).__name__}: {e}")
else:
print(contenido)
finally:
print("Este bloque se ejecuta SIEMPRE (para limpieza, cerrar recursos, etc.).")
La última clausula except, es una captura genérica, que recogería cualquier otra excepción que no se halla chequeado antes.
Clausula else
Más correcto sería emplear el bloque else para que se ejecuten las instrucciones en el caso de que no se produzca ninguna excepción:
fichero="Planetas.txt"
try:
with open(fichero) as objetoFichero:
contenido=objetoFichero.read()
except FileNotFoundError:
print("Ufff, parece que el fichero ",fichero," no existe")
else:
print(contenido)
Clausula finally
Las instrucciones en el bloque finally siempre se ejecutan, haya o no excepción, incluso si hay return en try/except. Conviene usarla cuando tengamos que garantizar alguna operación de limpieza, halla o no éxito. Por ejemplo, cerrar un fichero o cerrar una conexión a una base de datos.
Ejemplo:
f = open("data.txt")
try:
data = f.read()
except FileNotFoundError:
print("Archivo no encontrado")
finally:
f.close()
Encadenamiento(raise, raise from)
El encadenamiento y relanzamiento de excepciones en Python permite propagar errores con contexto. Se puede atrapar una excepción de bajo nivel, añadir información útil y volver a lanzarla. Con raise se relanza la excepción actual o una nueva, y con raise from se crea un encadenamiento explícito que preserva la causa original, lo que facilita el diagnóstico de errores.
def cargar_config(ruta):
try:
import json
with open(ruta, "r", encoding="utf-8") as fh:
return json.load(fh)
except FileNotFoundError as e:
raise RuntimeError("No se pudo cargar la configuración") from e
try:
cargar_config("config.json")
except RuntimeError as e:
print(f"Fallo: {e} (causa: {e.__cause__})")
Excepciones frecuentes
Las excepciones más habituales que podemos encontrarnos son:
Excepción
¿Cuándo ocurre?
Ejemplo
ValueError
Valor con tipo correcto pero contenido inválido
int(‘abc’)
TypeError
Operación no soporta por el tipo de objeto al que se aplicada
‘a’ + 5
KeyError
Clave inexistente en diccionario
d[‘x’]
IndexError
Índice fuera de rango
[1,2][7]
FileNotFoundError
Fichero no se encuentra en la ruta indicada
open(‘data.txt’)
PermissionError
Sin permisos de acceso
open(‘/root/privado’)
ZeroDivisionError
División por cero
7/0
OSError
Errores de sistema/IO
os.remove(‘bloqueado’)
KeyboardInterrupt
Interrupción manual (Ctrl+C)
Tabla de excepciones más comunes
NOTA:
Este post es parte de la colección “Python”. Puedes ver el índice de esta colección aquí.
Aquí dejo una propuesta de ejercicios con Clases y Objetos en python, para practicar lo aprendido en el post de Clases y Objetos.
Ejercicio 1: Clase Dispositivos e hijas
Define una clase Dispositivo con los atributos: marca, modelo y precio. Luego, crea las clases hijas: Smartphone, Tablet y Portatil, que hereden de Dispositivo y añade al menos un atributo específico a cada una de ellas.
Crea un objeto de cada clase hija (3 objetos en total) y pinta por pantalla todos los parámetros de uno de ellos.
Solución propuesta:
class Dispositivo:
def __init__(self, marca, modelo, precio):
self.marca = marca
self.modelo = modelo
self.precio = precio
class Smartphone(Dispositivo):
def __init__(self, marca, modelo, precio, sistema_operativo):
super().__init__(marca, modelo, precio)
self.sistema_operativo = sistema_operativo
class Tablet(Dispositivo):
def __init__(self, marca, modelo, precio, tamano_pantalla):
super().__init__(marca, modelo, precio)
self.tamano_pantalla = tamano_pantalla
class Portatil(Dispositivo):
def __init__(self, marca, modelo, precio, capacidad_almacenamiento):
super().__init__(marca, modelo, precio)
self.capacidad_almacenamiento = capacidad_almacenamiento
# Crear objetos de cada clase hija
smartphone = Smartphone("Samsung", "Galaxy S20", 999, "Android")
tablet = Tablet("Apple", "iPad Pro", 799, "12.9 pulgadas")
portatil = Portatil("Dell", "XPS 13", 1299, "512 GB SSD")
# Imprimir todos los parámetros de uno de los objetos
print("Marca:", smartphone.marca)
print("Modelo:", smartphone.modelo)
print("Precio:", smartphone.precio)
print("Sistema Operativo:", smartphone.sistema_operativo)
Ejercicio 2: Clase Rectángulo y Clase Punto
Crea una clase llamada «Punto» que tenga los atributos «x» e «y». Crea otra clase llamada «Rectangulo», que tiene como parámetros dos objetos de tipo Punto.
La clase Rectangulo debe implementar un método que calcule el área del rectángulo a partir de sus dos parámetros Punto.
El programa, empleando las clases anteriores, debe crear dos objetos punto y presentar por pantalla el área del rectángulo formado por los dos puntos.
NOTA: Lógicamente el área se calcula multiplicando las diferencias entre las coordenadas x e y de ambos puntos.
Por ejemplo:
Punto 1: (3,5) y Punto 2: (1,1)
Diferencias coordenadas x = 2, diferencias coordenadas y = 4
Area = 8
Si alguna de las diferencias de coordenadas fuera igual a cero, se indica por pantalla que no puede calcularse el área.
Solución propuesta:
class Punto:
def __init__(self, x, y):
self.x = x
self.y = y
class Rectangulo:
def __init__(self, punto1, punto2):
self.punto1 = punto1
self.punto2 = punto2
def calcular_area(self):
diferencia_x = abs(self.punto1.x - self.punto2.x)
diferencia_y = abs(self.punto1.y - self.punto2.y)
if diferencia_x == 0 or diferencia_y == 0:
print("No se puede calcular el área, una de las diferencias de coordenadas es igual a cero.")
else:
area = diferencia_x * diferencia_y
print("El área del rectángulo formado por los puntos es:", area)
# Crear dos objetos de tipo Punto
punto1 = Punto(3, 5)
punto2 = Punto(1, 1)
# Crear objeto de tipo Rectangulo con los dos puntos
rectangulo = Rectangulo(punto1, punto2)
# Calcular y mostrar el área del rectángulo
rectangulo.calcular_area()
Ejercicio 3: Clase Usuario de Red Social
Crea una clase UsuarioRedSocial para representar a los usuarios de una red social. La clase tiene los siguientes atributos: el nombre del usuario, una lista de amigos y una lista de publicaciones (llámalos con los nombres de variables que quieras). La clase debe incluir un método que pinte por pantalla todos los parámetros del objeto UsuarioRedSocial, incluyendo los amigos que tiene y las publicaciones que ha hecho.
El programa pide al usuario que introduzca su nombre, los nombres de 3 amigos y los títulos de 3 publicaciones que haya hecho en la red Social. A continuación, con los datos introducidos crea un objeto UsuarioRedSocial y pinta por pantalla los parámetros del objeto, empleando el método de la clase UsuarioRedSocial.
Solución propuesta:
class UsuarioRedSocial:
def __init__(self, nombre, amigos, publicaciones):
self.nombre = nombre
self.amigos = amigos
self.publicaciones = publicaciones
def mostrar_info(self):
print("Nombre:", self.nombre)
print("Amigos:", ', '.join(self.amigos))
print("Publicaciones:")
for publicacion in self.publicaciones:
print("- ", publicacion)
# Solicitar al usuario que introduzca sus datos
nombre = input("Introduce tu nombre: ")
amigos = [input("Introduce el nombre de un amigo: ") for _ in range(3)]
publicaciones = [input("Introduce el título de una publicación: ") for _ in range(3)]
# Crear un objeto UsuarioRedSocial con los datos introducidos
usuario = UsuarioRedSocial(nombre, amigos, publicaciones)
# Mostrar la información del usuario
usuario.mostrar_info()
Ejercicio 4: Personajes de un juego
Define una clase Personaje para representar a los personajes de un juego. La clase tiene los atributos: nombre del personaje, nivel alcanzado y puntos de vida (llámalos con los nombres de variables que quieras). Luego, crea las clases hijas: Guerrero y Mago con al menos un parámetro específico para cada una de ellas.
El programa pregunta al usuario si quiere crear un Personaje Guerrero o Mago. En función de lo que indique el usuario, el programa pide al usuario los datos necesarios para crear el objeto y lo crea. Finalmente, indica por pantalla que el objeto ha sido creado y pinta los parámetros del objeto.
Solución propuesta:
class Personaje:
def __init__(self, nombre, nivel, puntos_vida):
self.nombre = nombre
self.nivel = nivel
self.puntos_vida = puntos_vida
def mostrar_info(self):
print("Nombre del personaje:", self.nombre)
print("Nivel alcanzado:", self.nivel)
print("Puntos de vida:", self.puntos_vida)
class Guerrero(Personaje):
def __init__(self, nombre, nivel, puntos_vida, arma):
super().__init__(nombre, nivel, puntos_vida)
self.arma = arma
class Mago(Personaje):
def __init__(self, nombre, nivel, puntos_vida, hechizo):
super().__init__(nombre, nivel, puntos_vida)
self.hechizo = hechizo
# Solicitar al usuario qué tipo de personaje quiere crear
tipo_personaje = input("¿Quieres crear un Personaje Guerrero o Mago? ").lower()
# Solicitar al usuario los datos necesarios para crear el personaje
nombre = input("Introduce el nombre del personaje: ")
nivel = int(input("Introduce el nivel alcanzado del personaje: "))
puntos_vida = int(input("Introduce los puntos de vida del personaje: "))
# Crear el objeto correspondiente al tipo de personaje elegido por el usuario
if tipo_personaje == "guerrero":
arma = input("Introduce el arma del guerrero: ")
personaje = Guerrero(nombre, nivel, puntos_vida, arma)
elif tipo_personaje == "mago":
hechizo = input("Introduce el hechizo del mago: ")
personaje = Mago(nombre, nivel, puntos_vida, hechizo)
else:
print("Tipo de personaje no válido.")
# Mostrar que el objeto ha sido creado y pintar los parámetros del objeto
if tipo_personaje in ["guerrero", "mago"]:
print("El personaje {} ha sido creado:".format(tipo_personaje.capitalize()))
personaje.mostrar_info()
Ejercicio 5: Clases Barco y Velero
Define una clase llamada Barco con los parámetros: eslora y manga. Define además otra clase llamada Velero que herede de la clase Barco y que tenga un parámetro: el número de velas. La clase Velero tiene que tener un método que calcule el precio del atraque que será igual a: ((eslora x manga) + (número de velas x 10))
El programa tiene que crear dos objetos Veleros y presentar por pantalla los datos de ambos veleros. Además, indicar para que velero es más barato el precio del atraque.
Solución propuesta:
class Barco:
def __init__(self, eslora, manga):
self.eslora = eslora
self.manga = manga
class Velero(Barco):
def __init__(self, eslora, manga, num_velas):
super().__init__(eslora, manga)
self.num_velas = num_velas
def calcular_precio_atraque(self):
return (self.eslora * self.manga) + (self.num_velas * 10)
# Crear dos objetos Velero
velero1 = Velero(10, 5, 3)
velero2 = Velero(8, 4, 4)
# Mostrar los datos de ambos veleros
print("Datos del Velero 1:")
print("Eslora:", velero1.eslora)
print("Manga:", velero1.manga)
print("Número de velas:", velero1.num_velas)
print("Precio del atraque:", velero1.calcular_precio_atraque())
print("\nDatos del Velero 2:")
print("Eslora:", velero2.eslora)
print("Manga:", velero2.manga)
print("Número de velas:", velero2.num_velas)
print("Precio del atraque:", velero2.calcular_precio_atraque())
# Comparar precios de atraque
if velero1.calcular_precio_atraque() < velero2.calcular_precio_atraque():
print("\nEl Velero 1 tiene un precio de atraque más barato.")
elif velero1.calcular_precio_atraque() > velero2.calcular_precio_atraque():
print("\nEl Velero 2 tiene un precio de atraque más barato.")
else:
print("\nAmbos veleros tienen el mismo precio de atraque.")
Ejercicio 6: Clases Vuelo y Avión
Crea una clase Vuelo para representar los vuelos de una aerolínea. La clase tendrá los atributos: número de vuelo, número de pasajeros y destino. Implementa otra clase llamada Avion que tenga los parámetros: número de asientos y lista de destinos.
El programa pide al usuario que introduzca la información de un Vuelo y de un Avion. Con la información introducida, crea un objeto Vuelo y otro objeto Avion. Y empleando los parámetros de ambos objetos, indica si se puede asignar el avión al vuelo. Lógicamente, para que se pueda asignar un avión a un vuelo, el número de asientos del avión tiene que ser igual o superior al número de pasajeros y el destino del vuelo tiene que estar en la lista de destinos del avión.
Solución propuesta:
class Vuelo:
def __init__(self, numero_vuelo, num_pasajeros, destino):
self.numero_vuelo = numero_vuelo
self.num_pasajeros = num_pasajeros
self.destino = destino
class Avion:
def __init__(self, num_asientos, destinos):
self.num_asientos = num_asientos
self.destinos = destinos
# Solicitar al usuario la información del vuelo
numero_vuelo = input("Introduce el número de vuelo: ")
num_pasajeros = int(input("Introduce el número de pasajeros: "))
destino_vuelo = input("Introduce el destino del vuelo: ")
# Solicitar al usuario la información del avión
num_asientos = int(input("Introduce el número de asientos del avión: "))
destinos_avion = input("Introduce la lista de destinos del avión separados por comas: ").split(',')
# Crear objetos Vuelo y Avion
vuelo = Vuelo(numero_vuelo, num_pasajeros, destino_vuelo)
avion = Avion(num_asientos, destinos_avion)
# Comprobar si se puede asignar el avión al vuelo
if vuelo.num_pasajeros <= avion.num_asientos and vuelo.destino in avion.destinos:
print("El avión puede ser asignado al vuelo.")
else:
print("El avión no puede ser asignado al vuelo.")
Ejercicio 7: Clase Vivienda y clase Chalet
Crea una clase llamada Vivienda con los parámetros: año de construcción, metros cuadrados habitables y precio. Crea otra clase llamada Chalet que herede de Vivienda y que tenga un único parámetro: piscina (un booleano que indica si el chalet tiene piscina).
La clase Chalet tiene un método para calcular el máximo de hipoteca que se le puede conceder. Este método sigue la lógica siguiente: Si el chalet tiene piscina, el máximo de hipoteca que se puede conceder es cero, si no la tiene, el máximo de hipoteca es el precio por metro cuadrado multiplicado por 100 (el precio por metro cuadrado se obtiene dividiendo los metros cuadrados habitables entre el precio).
El programa pide al usuario que introduzca los datos de un Chalet, crea un objeto Chalet con los datos introducidos, y empleando la función de la clase Chalet presenta por pantalla el máximo de hipoteca para ese Chalet.
Solución propuesta
class Vivienda:
def __init__(self, ano_construccion, metros_cuadrados, precio):
self.ano_construccion = ano_construccion
self.metros_cuadrados = metros_cuadrados
self.precio = precio
class Chalet(Vivienda):
def __init__(self, ano_construccion, metros_cuadrados, precio, piscina):
super().__init__(ano_construccion, metros_cuadrados, precio)
self.piscina = piscina
def calcular_max_hipoteca(self):
if self.piscina:
return 0
else:
return (self.precio / self.metros_cuadrados) * 100
# Solicitar al usuario que introduzca los datos del Chalet
ano_construccion = int(input("Introduce el año de construcción del chalet: "))
metros_cuadrados = float(input("Introduce los metros cuadrados habitables del chalet: "))
precio = float(input("Introduce el precio del chalet: "))
piscina = input("El chalet tiene piscina (si/no): ").lower() == "si"
# Crear objeto Chalet con los datos introducidos
chalet = Chalet(ano_construccion, metros_cuadrados, precio, piscina)
# Calcular y mostrar el máximo de hipoteca para el Chalet
max_hipoteca = chalet.calcular_max_hipoteca()
print("El máximo de hipoteca para este chalet es:", max_hipoteca)
Ejercicio 8: Clase Coche e hijas
Define una clase llamada Coche con los parámetros marca y modelo. Luego, define otra clase llamada Deportivo que herede de la clase Coche y que tenga un parámetro adicional: potencia. La clase Deportivo debe tener un método que calcule el precio del seguro, el cual será igual a la potencia del coche multiplicada por 20 más un extra de 1000 euros.
El programa debe crear dos objetos Deportivo y mostrar por pantalla los datos de ambos coches. Además, debe indicar cuál de los dos coches tiene un seguro más barato.
Solución propuesta:
class Coche:
def __init__(self, marca, modelo):
self.marca = marca
self.modelo = modelo
class Deportivo(Coche):
def __init__(self, marca, modelo, potencia):
super().__init__(marca, modelo)
self.potencia = potencia
def calcular_precio_seguro(self):
return (self.potencia * 20) + 1000
# Crear dos objetos Deportivo
deportivo1 = Deportivo("Ferrari", "Testarossa", 500)
deportivo2 = Deportivo("Porsche", "911", 400)
# Mostrar los datos de ambos coches deportivos
print("Datos del Deportivo 1:")
print("Marca:", deportivo1.marca)
print("Modelo:", deportivo1.modelo)
print("Potencia:", deportivo1.potencia)
print("Precio del seguro:", deportivo1.calcular_precio_seguro())
print("\nDatos del Deportivo 2:")
print("Marca:", deportivo2.marca)
print("Modelo:", deportivo2.modelo)
print("Potencia:", deportivo2.potencia)
print("Precio del seguro:", deportivo2.calcular_precio_seguro())
# Indicar cuál de los dos coches tiene un seguro más barato
if deportivo1.calcular_precio_seguro() < deportivo2.calcular_precio_seguro():
print("\nEl Deportivo 1 tiene un seguro más barato.")
elif deportivo1.calcular_precio_seguro() > deportivo2.calcular_precio_seguro():
print("\nEl Deportivo 2 tiene un seguro más barato.")
else:
print("\nAmbos coches tienen el mismo precio de seguro.")
NOTA:
Este post es parte de la colección “Python”. Puedes ver el índice de esta colección aquí.